毕业论文写作中的工具使用经验
本贴叙述我在使用ThuThesis模板写毕业论文中遇到的一些技术性问题及其解决方案。希望给大家带来帮助,少走一些弯路。
参考文献相关
- 查找bibtex中固定字段。应用场景为将某些工具导出的bibitem中的note,abstract, keyword, volume等删去
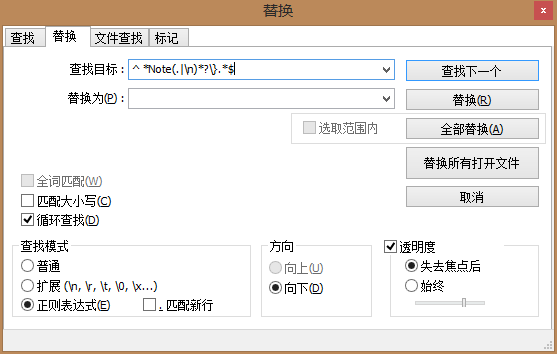
以Note字段为例,正则表达式为
^ *Note(.|\n)*?\}.*$,可以匹配多行的一个字段,?为非贪婪匹配。经测试在Notepad++里可以正常使用该正则表达式。需要删去该字段时只需要将匹配的替换成空字符串即可。
- 我系一些同学参考文献是手动输入的bib item,当需要批量下载bibtex文件时可以使用一些自动化脚本。从bib item中自动爬出题目及使用scholar.py自动从Google Scholar下载bibitem的的脚本参见https://gist.github.com/haccanri/eac4e7b83e11ae05e3b0。
- 推一个Chrome浏览器的插件,可以搜索文献,大量使用Google Scholar的时候会方便一些。链接https://chrome.google.com/webstore/detail/google-scholar-button/ldipcbpaocekfooobnbcddclnhejkcpn
- 如果ThuThesis的bib style不能满足系里各种奇葩的需求,最后一招是手动修改
.bbl文件,修改成任何你想要的格式,然后只编译tex,不要修改bib文件也不要编译bib就可以得到最终的参考文献格式。在修改好.bbl文件之后最好备份一下,以免误操作重新编译bib覆盖了.bbl文件。 - 参考文献Title大小写。考虑到之前投稿论文的参考文献要求,我在论文题目中仅保留了第一个单词首字母大写,剩下的小写。有以下几个例外情况:
- 专有名词,如”NP problem”
- 冒号后面的第一个单词,比如Something in title: A case study
- 书的名字,
@book中题目除虚词外每个单词都保留首字母大写
处理大小写我使用了网上的一个perl脚本, 使用
perl lc.pl file可以完成上面的除第三条以外的其他大小写转换,有以下几点要注意 - 在windows系统中,要把system命令里面的cp和rm命令改为对应的copy和del命令 -file为不带后缀名的文件名,也就是要处理test.tex时file为’test’。不知道作者为什么设置得这么诡异。 - 处理完有一些小的bug,比如Title中第一个单词有些全部大写的没有正确转换,比如”THE”,不知道是故意的还是bug - 上面第二条冒号规则需要手工处理,或许有空了可以改进吧,不过perl脚本不太愿意看有些Latex bib style本身也会对大小写做些处理,比如只保留首字母大写,这时如果想手工保留某些专有名词的大写,可以给大写字符串专门加上大括号,比如
{NP}。JabRef软件可以自动做这样的处理。 - 参考文献引用到一本书具体的页面,并且显示在上标里,参见这个页面,修改cls文件里对应的语句即可。
零散的Latex命令及小技巧
\verb|XXX|可以原文引入XXX处的文字,适合转义比较多且不包含命令的情况。\textt{}貌似可以处理里面包含命令的情况,没有测试\linespread{1.1}可以修改行距,1.0是原本的行距,1.1是之前的1.1倍。这个可以高效地调整页数,一般1.1倍行距肉眼很难看出来。 在投会议论文时,由于页数限制,往往压缩的时候大招就是使用\linespread{0.95}之类的。不到万不得已,最好不要使用这招。- 如果写作的过程中需要给之后的写作提个醒,但在最终版中方便地去掉,有以下几种方式来加上类似于Todo标签
- 最简单不折腾的办法是,用注释
%todo来标注出来。在TeXstuio软件中会在结构树中自动罗列出%todo标识的todo标签。 -
自己定义一个简单的todo命令来标识,通过设置类似于debug开关的选项来决定是否在pdf中输出。
\newcommand{\todo}[1]{} %comment not showed %\newcommand{\todo}[1]{\color{blue} #1} %comment showed需要显示的话注释第一条,最终打印版本注释第二条(代码中所示)。comment的格式可以在命令中自己修改。代码中使用的是蓝色来标识的,需要使用xcolor这个包。 - 可以使用todonotes等专业的tex package来完成,但如果只是给自己看的话真心没必要折腾这个。
- 最简单不折腾的办法是,用注释
- 一个可以把Excel中的表格转换为Tex代码的Excel加载项。虽然逻辑很简单,但非常实用。矩阵等也可以用这个来处理。下载链接为https://www.ctan.org/tex-archive/support/excel2latex/
Latex中文编码
- 模板及Tex文件默认是GB18030编码,用pdflatex编译没问题。但是在GitHub for windows中是乱码,因为GitHub for windows目前只支持标准utf8。本来想折腾下,后来放弃了。Git Gui可以支持GB18030编码,最后的方案是在这里看GB18030编码的diff。
- 将所有tex及模板文档改为utf-8直接用xeLatex编译会报错
Command \nobreakspace unavailable in encoding EU1。按照这个页面中的说明删掉xunicode引用,并且可以用xeLatex编译成功。但pdfLatex编译仍然失败,报错为! Argument of \HyPsd@GetTwoBytes has an extra。 - 终极解决方案是用CJKutf8 package并且用支持utf8的模板,鉴于我的论文模板不支持utf8,到这里决定不折腾了。以后想折腾可以参考以下页面
- 最新版的ThuThesis已经支持utf-8,不过貌似不太稳定(只能用xeLatex,pdfLatex需要安装字字体之类的比较麻烦),我编译出来的图片位置不对。不折腾了…
- 将所有tex及模板文档改为utf-8直接用xeLatex编译会报错
- 在编译tex之前执行
gbk2uni main.out命令可以解决书签中文乱码的问题。可以在TeXstudio中自定义一个命令,绑定快捷键使用起来会很方便。如果导入我的设置文件的话可以在F1快捷编译之后,再按F2编译一次,就可以得到中文书签正常的pdf。自定义的命令其实是将gbk2uni main.out和编译命令结合在一起得到的,如下图所示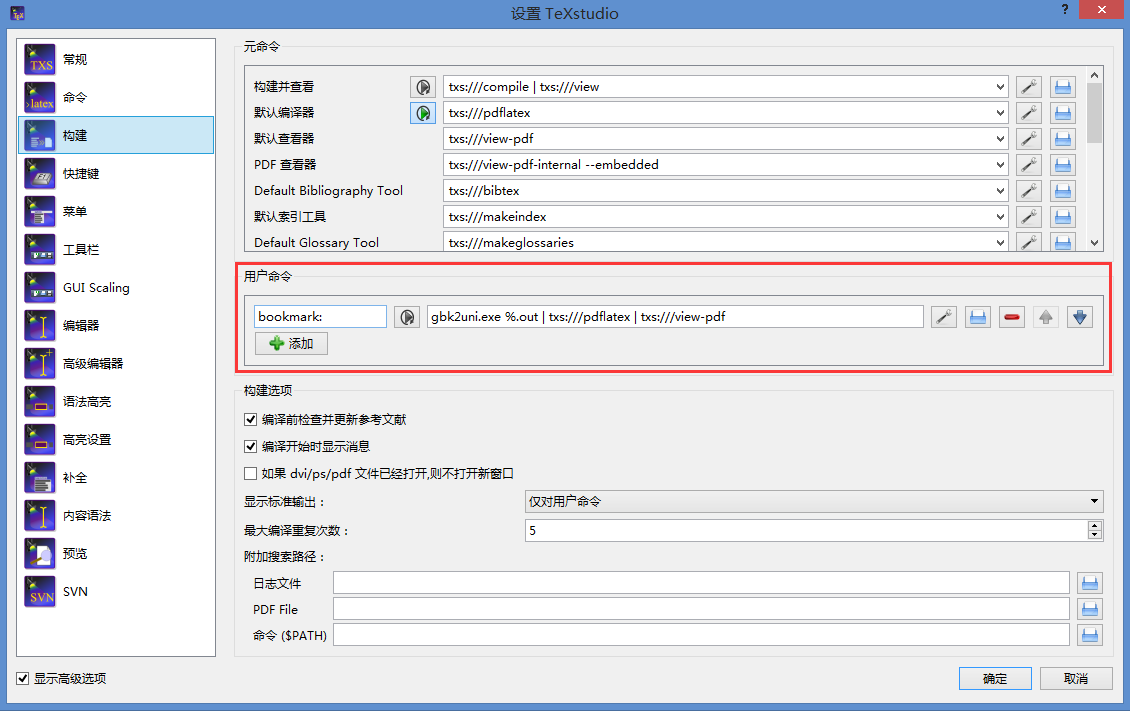
- 用Python和Matplotlib画图中有中文的情况请参考页面1和页面2,我是两种方法结合在一起最后实现的显示中文。